
We will continue our example, we will analyze the data of the files , clean and transform the data from bronze schema. we will analyze the tables staff, staff_schedule and services_weekly.
staff
we will select the role unique values from staff table :
select distinct role
FROM bronze.staff s;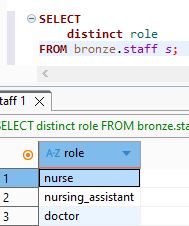
we will select the service unique values from staff table :
SELECT distinct s.service
FROM bronze.staff s;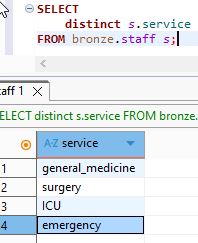
staff_schedule
we will select the role unique values from staff table :
select distinct role
from bronze.staff_schedule;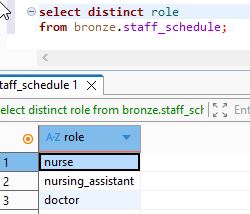
we will select the service unique values from staff table :
select distinct service
from bronze.staff_schedule;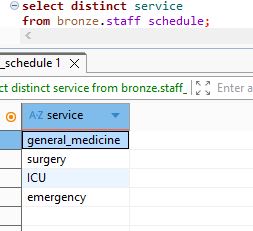
staff and staff_schedule
We will analyze the join between staff and staff schedule:
Join by id
both tables have staff_id field lets check if they have the same values :
select count(*)
FROM bronze.staff s
inner JOIN bronze.staff_schedule ss
ON s.staff_id = ss.staff_id ;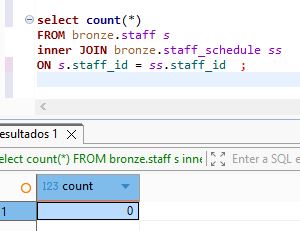
We see that the id are not correlated.
lets join by name :
select count(distinct s.staff_name)
FROM bronze.staff s
inner JOIN bronze.staff_schedule ss
ON s.staff_name = ss.staff_name ;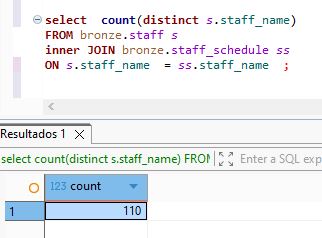
lets count staff and staff_schedule
select count(distinct staff_name)
from bronze.staff s;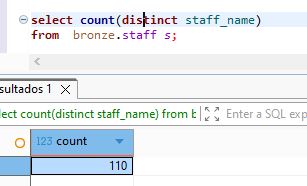
we can see that the table staff_schedule have more rows 16 more than staff table
select count(distinct staff_name)
from bronze.staff_schedule ss ;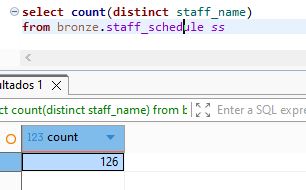
Lets see if the name and role are the same in both table , because in real life staff member doesn’t change they roles. And as we see this hospital have 4 services is not a small hospital.
SELECT
distinct s.staff_name , s."role" staff_role , ss.role staff_schedule_role
FROM bronze.staff s
inner JOIN bronze.staff_schedule ss
ON s.staff_name = ss.staff_name
where s."role"<> ss.role
order by 1;
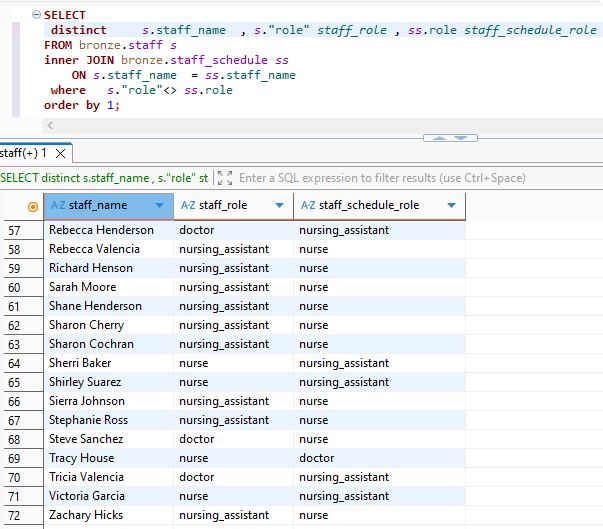
So we have 72 mistakes.
Next post we will continue the data analysis.
Links:
Leave a Reply
You must be logged in to post a comment.